
شو يعني "تعلم" أصلاً؟ 🤔
قبل ما نحكي عن الماكينة، خلينا نفهم شو يعني تعلم للبشر:
تعريف "هربرت سيمون": التعلم هو التغيرات اللي بتصير بالنظام
وبتخليه يقدر يعمل نفس المهمة بكفاءة أعلى في المرات الجاية. يعني
مش بكرر وبس، بل بتحسن!
أما بالماكينة (ML): هو قدرة النظام على "الاكتساب التلقائي" و
"دمج المعرفة" بدون تدخل بشري في كل خطوة.

تعلم الآلة بالمعنى الحرفي
ببساطة، هي تكنولوجيا بتعلم الكمبيوتر كيف ينفذ مهام عن طريق التعلم من
البيانات بدل ما نبرمجه كود كود (Explicitly programmed).
الهدف النهائي؟ إننا نخلي النظام "يتوقع" (Predictions) بدقة لما نعطيه بيانات جديدة ما شافها من قبل. 🎯
الهدف النهائي؟ إننا نخلي النظام "يتوقع" (Predictions) بدقة لما نعطيه بيانات جديدة ما شافها من قبل. 🎯

يا ترى شو الأشياء اللي العلم بيتوقعها؟
شوف هاي الأمثلة اللي بالسلايد، هي حرفياً حياتنا اليومية:
- 🍏 تمييز الأشياء: هاي صورة تفاحة ولا موزة؟
- 🚗 سيارات ذاتية القيادة: تمييز الناس اللي بتقطع الشارع عشان توقف.
- 📖 فهم الكلام: هل كلمة book هون معناها كتاب ولا "حجز" فندق؟
- 📧 البريد المزعج: هل هذا الإيميل Spam ولا إيميل شغل مهم؟
- 🗣️ كلام ليوتيوب: تحويل الكلام اللي بنحكيه لترجمة مكتوبة بدقة عالية.

الـ AI ولا الـ ML؟ شو الفرق؟ 🤔
ركز بالرسمة (Venn Diagram)، هي بتشرح لك كل القصة:
Artificial Intelligence (AI): هو العلم الكبير "المظلة" اللي
هدفه محاكاة ذكاء البشر. أي إشي بخلي الكمبيوتر يبين ذكي هو AI.
Machine Learning (ML): هو "جزء" من الـ AI، هو الطريقة اللي
بنعلم فيها الكمبيوتر كيف يتعلم لحاله من البيانات بدل ما نعطيه قوانين ثابتة.
Deep Learning (DL): (اللون الغامق بالنص) هو "جزء" من الـ ML،
بستخدم طبقات معقدة (شبكات عصبية) عشان يتعلم من كميات ضخمة من البيانات.
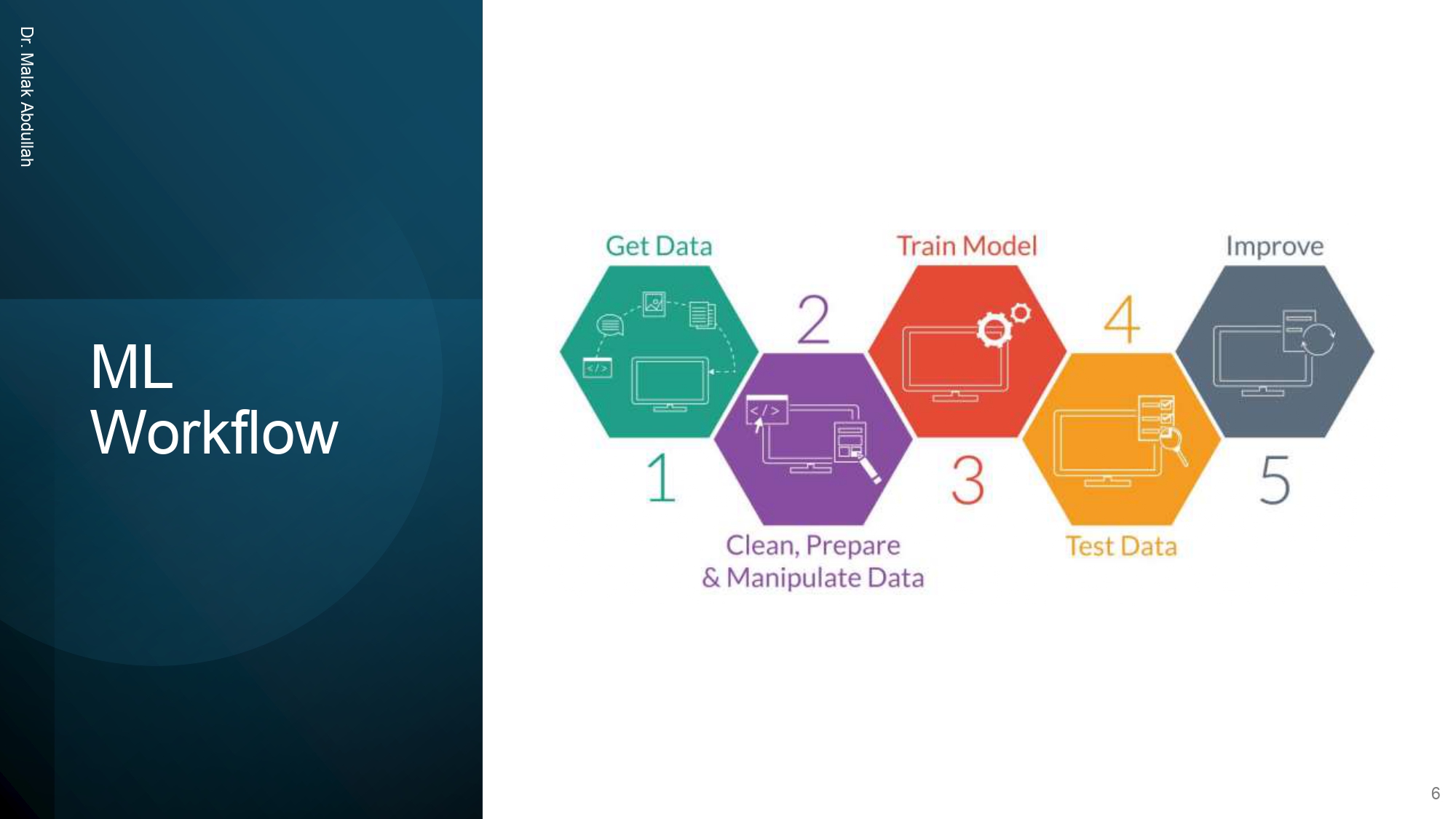
كيف بيمشي الشغل فعلياً؟ (Workflow) ⚙️
العملية عبارة عن 5 خطوات أساسية ومرتبة:
1. Get Data: نلم البيانات من المصادر.
2. Clean, Prepare & Manipulate: ننظف الداتا ونرتبها (أصعب
مرحلة!).
3. Train Model: ندرب الخوارزمية على البيانات.
4. Test Data: نختبر الموديل ببيانات جديدة عشان نتأكد من شطارته.
5. Improve: نعدل ونحسن لنوصل لأفضل نتيجة ممكنة.

أنواع خوارزميات الـ ML 📂
خوارزميات تعلم الآلة بنقسمها لـ 4 عائلات أساسية:
Supervised Learning: بنعطي الجهاز بيانات "معلومة" (Labeled).. يعني بنقوله هاي صورة بسة وهاي صورة كلب، وهو بتعلم يفرق
بينهم.
Unsupervised Learning: هون بنرمي له البيانات وبنقوله "دبّر
حالك" استكشف الأنماط لحالك! وغالباً بكون البيانات مش معلومة.
Semi-supervised: خليط بينهم، شوية داتا معها ليبلات وباقي الداتا
"قرعة" بدون أسماء.
Reinforcement Learning: نظام "الثواب والعقاب".. الموديل بستكشف
البيئة وإذا عمل صح بنعطيه "جائزة" وإذا غلط بنعطيه "مخالفة" ليتعلم.
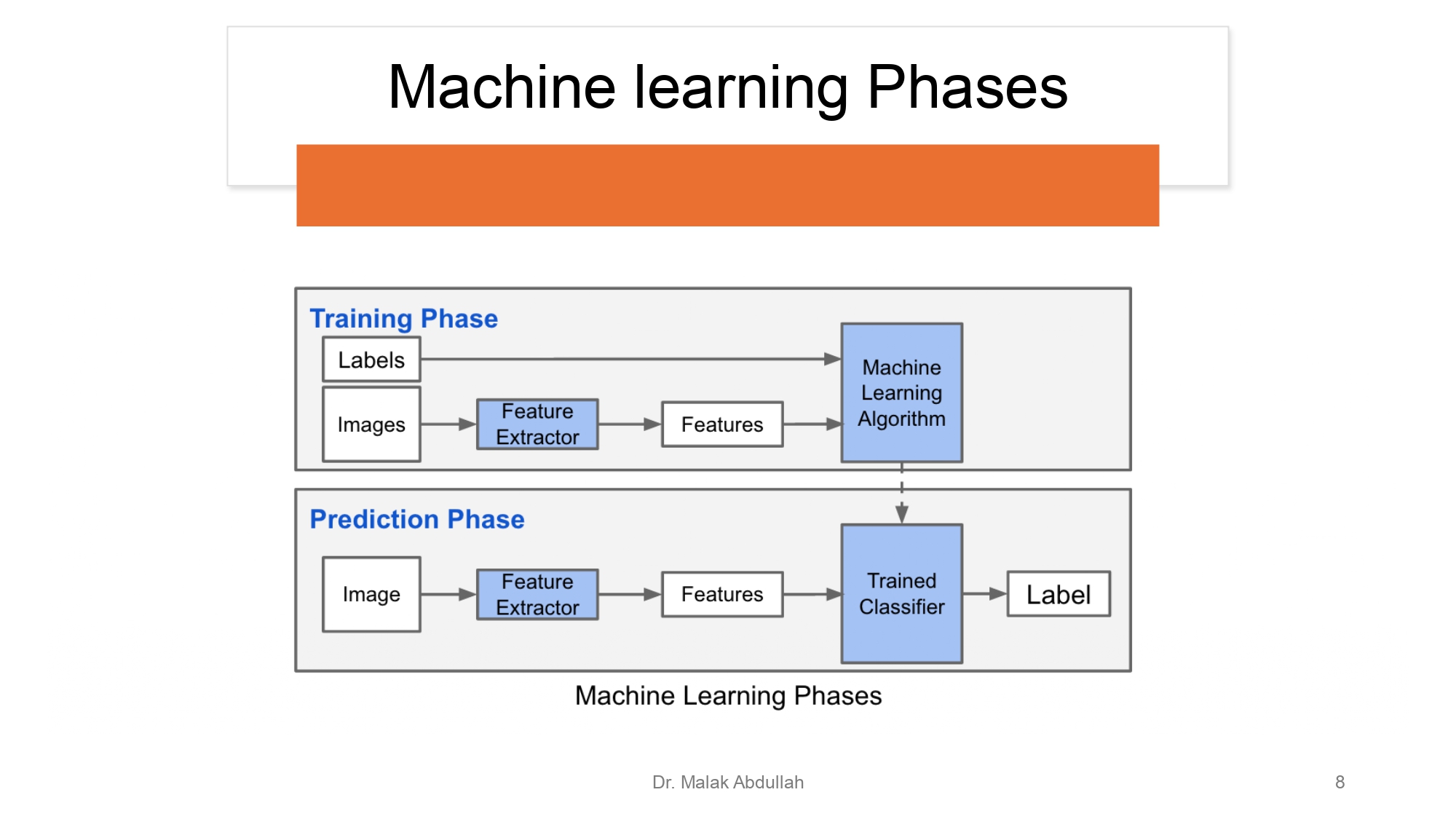
مراحل الـ ML (تدريب وتوقع) 🔄
الشغل بنقسم لمرحلتين كبار:
Training Phase: هون الموديل "بدرس".. بنعطيه الصور والـ Labels، وبنطلع منه "ميزات" (Features)
عشان يبني الخوارزمية تبعته.
Prediction Phase: هون فحص "يوم الامتحان".. بنعطيه صورة جديدة ما
شافها، وهو بستخدم اللي تعلمه (الـ Trained Classifier) عشان يطلع
"توقيع" أو Label صح.
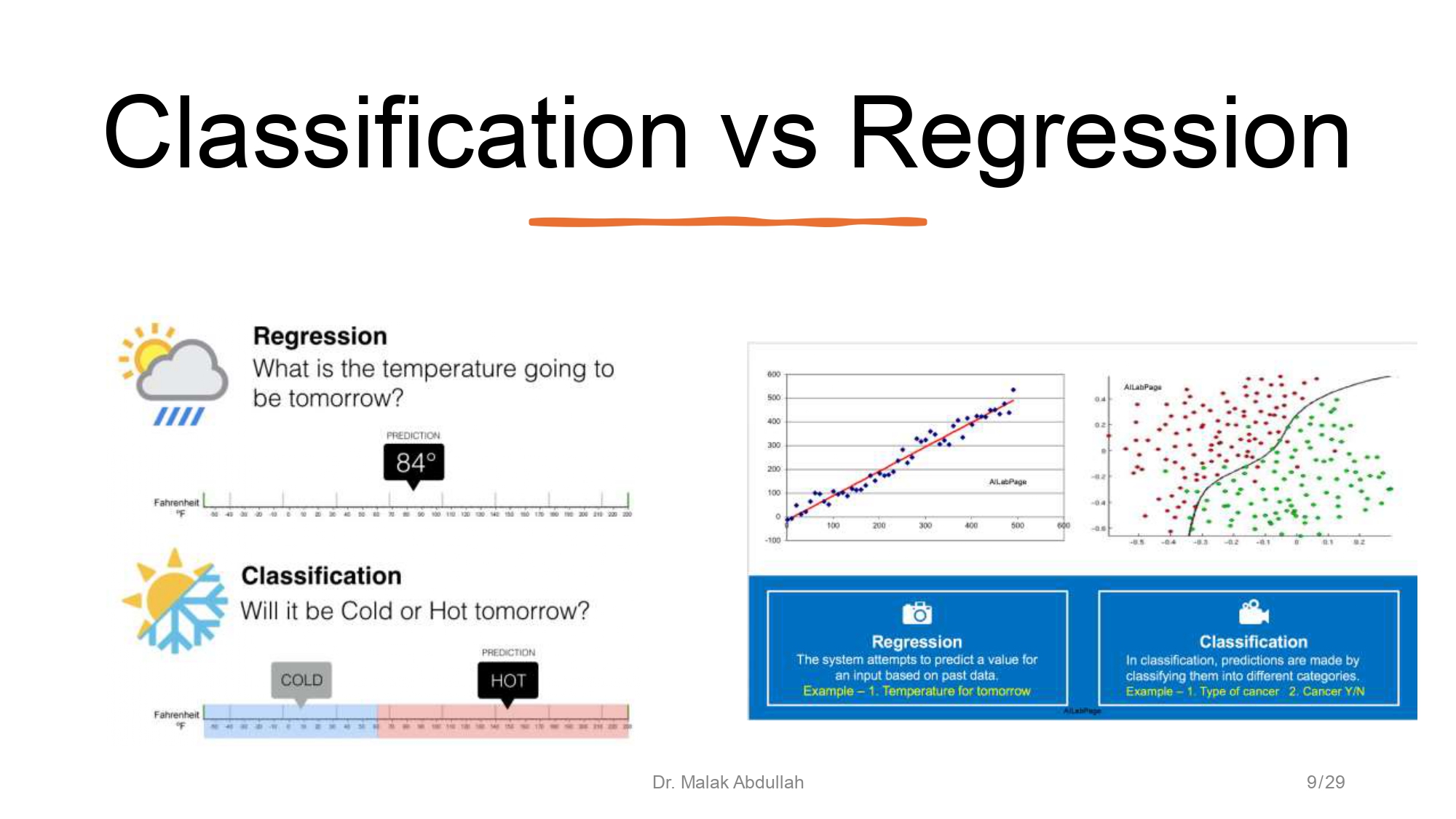
يا تصنيف.. يا رقم! (Classification vs Regression) ⚖️
في الـ Supervised Learning، عنا نوعين من المشاكل:
Regression (الانحدار): لما يكون الجواب "رقم".. مثلاً قديش درجة
الحرارة بكرة؟ 84؟ 20؟ رقم مستمر.
Classification (التصنيف): لما يكون الجواب "فئة" (Category).. الجو بكرة "برد" ولا "شوب"؟ في سرطان ولا ما في؟ أبيض ولا
أسود؟
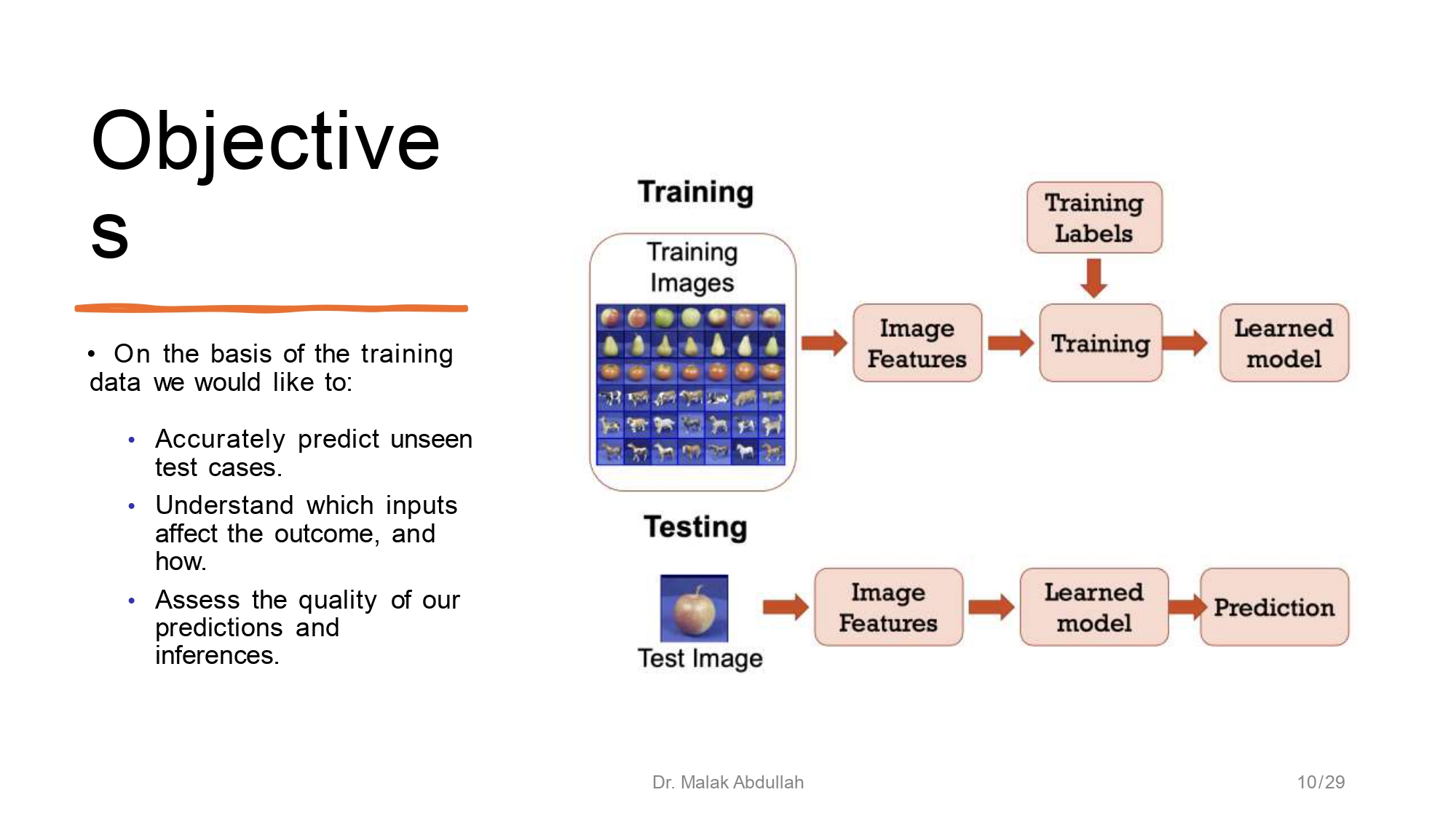
ليش بنعمل كل هاض؟ (الأهداف) 🥅
بناءً ع المعلومات اللي عنا، هدفنا نوصل لـ:
- توقع دقيق للحالات اللي ما شفناها من قبل (Unseen cases).
- نفهم "شو" المدخلات اللي بتأثر ع النتيجة وكيف بتأثر.
- نقيم جودة التوقعات تبعتنا ونحسنها.

تعريف التصنيف (Classification) بدقة 🎯
التصنيف هو إننا نعطي الموديل مجموعة عينات (Training set)، كل عينة فيها
"خصائص" (Attributes) و "فئة" (Class
label).
الهدف: نبني موديل يقدر يحزر الـ Class label لأي عينة جديدة. وعشان نختبره، بنقسم بياناتنا لـ Training set للتعلم و Test set للتقييم.
الهدف: نبني موديل يقدر يحزر الـ Class label لأي عينة جديدة. وعشان نختبره، بنقسم بياناتنا لـ Training set للتعلم و Test set للتقييم.
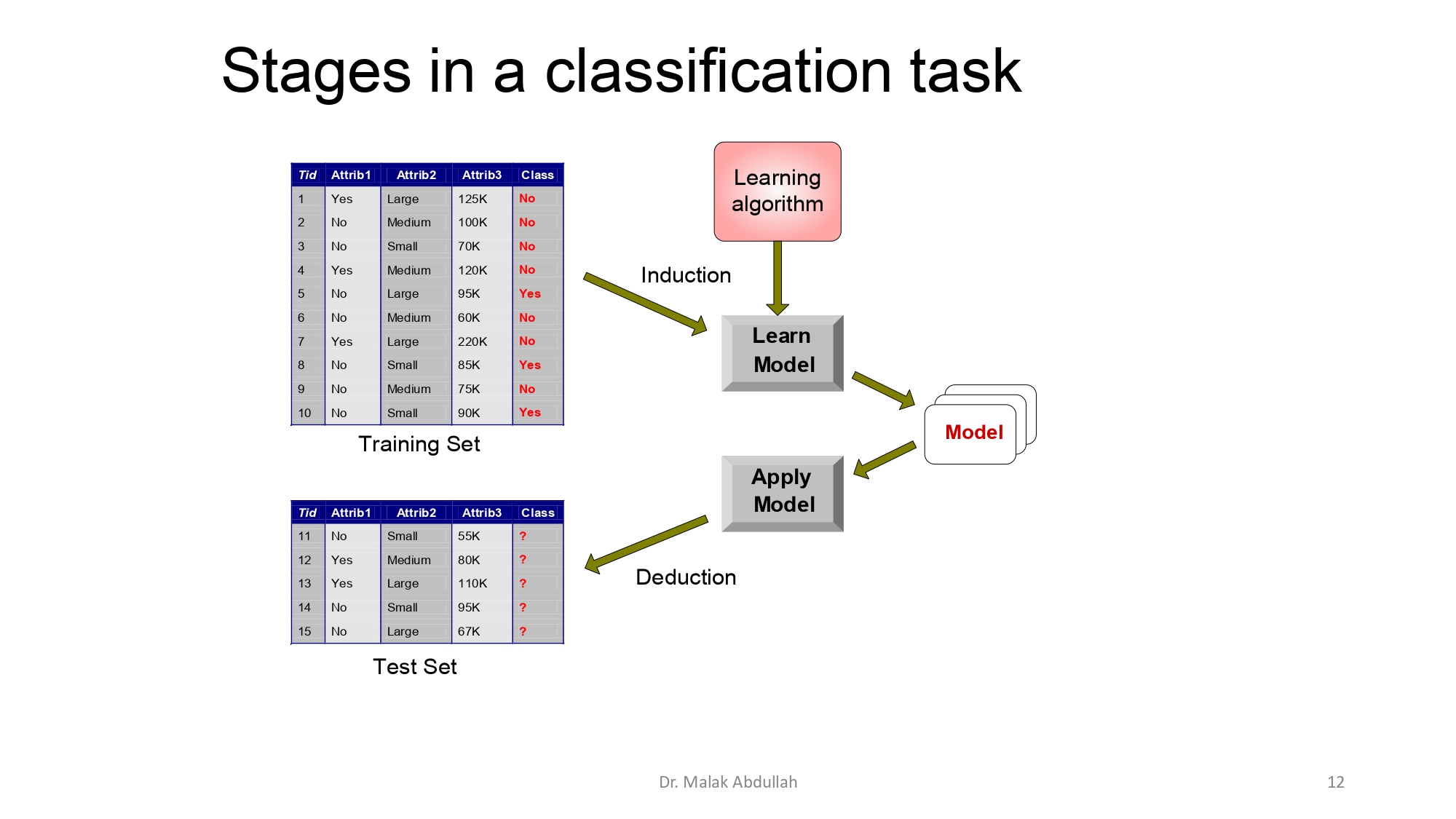
خطوات عملية التصنيف 🪜
العملية بتمشي في مسارين أساسيين زي ما إنت شايف بالرسمة:
Induction (الاستنتاج): بنجيب الـ Training Set (البيانات اللي فيها الحل)، وبندخلها ع الـ Learning Algorithm عشان نبني الموديل. هاي مرحلة "بناء المعرفة".
Deduction (الاستنباط): بنجيب الـ Test
Set (البيانات اللي ما بنعرف حلها)، وبنطبق عليها الموديل اللي بنيناه (Apply Model) عشان نطلع النتائج المتوقعة.

أشكال التصنيف المختلفة 🎭
مش كل التصنيف زي بعضه، عنا 3 أنواع رئيسية:
Binary Classification: جوابين بس! (آه أو لأ).. زي إيميل مزعج أو
لأ، ورم حميد أو خبيث.
Multiclass Classification: لما يكون عنا أكثر من خيار، بس بنختار
واحد بس! زي تصنيف صورة حيوان (كلب، قطة، حصان، عصفور).
Multi-label Classification: هون الصورة ممكن تاخذ أكثر من تصنيف
بنفس الوقت! زي صورة فيها Alice و Charlie مع بعض، الموديل لازم يطلع الإثنين.

التعميم (Generalization) 🧩
الهدف مش إن الموديل "يبصم" الداتا اللي أعطيناه إياها، الهدف إنه "يفهمها" عشان يقدر يحل داتا جديدة!
التعريف: هو قدرة الموديل على توقع الـ Class labels لبيانات ما شافها من
قبل (previously unseen).
كيف بنقيسه؟ بنستخدم الـ Test set
اللي الموديل ما لمسها خلال التدريب، وبنشوف دقة توقعاته.
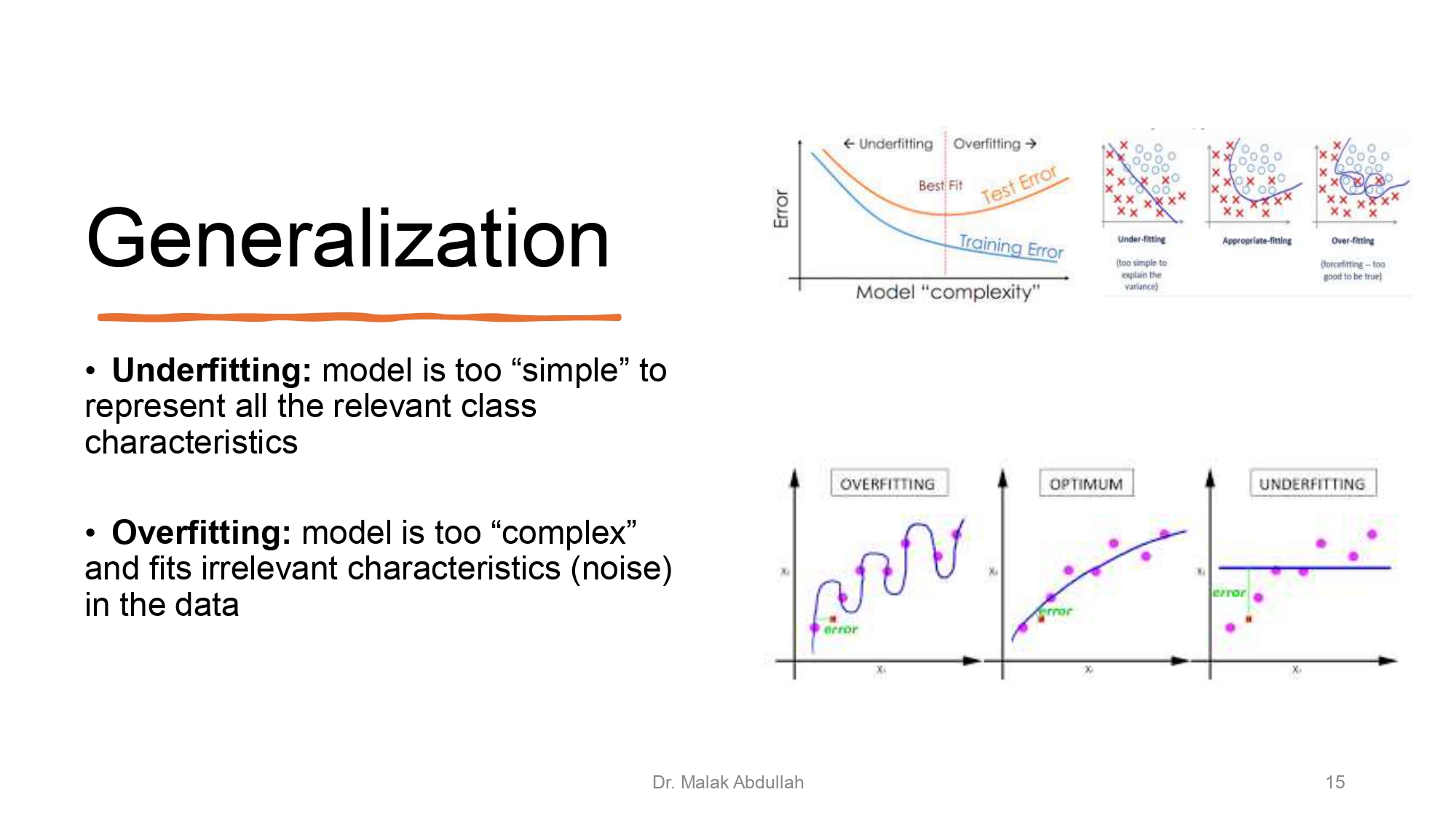
مشاكل التعميم (الأوفر والآندر فت) 🚩
لما الموديل يفشل في التعميم، بكون وقع في وحدة من هالمشكلتين:
Underfitting: الموديل "كثير بسيط" ومش فاهم إشي، زي طالب ما درس
بالمرة ودخل الامتحان. ما بقدر يمثل خصائص الداتا صح.
Overfitting: الموديل "بصيم" بزيادة! حفظ الداتا بالأخطاء اللي
فيها (الـ Noise)، فما بعرف يحل أي إشي بختلف شوي عن اللي حفظه.
Optimum (الأفضل): هو التوازن بالنص، موديل فاهم الأنماط الأساسية
وبقدر يعمم على داتا جديدة.
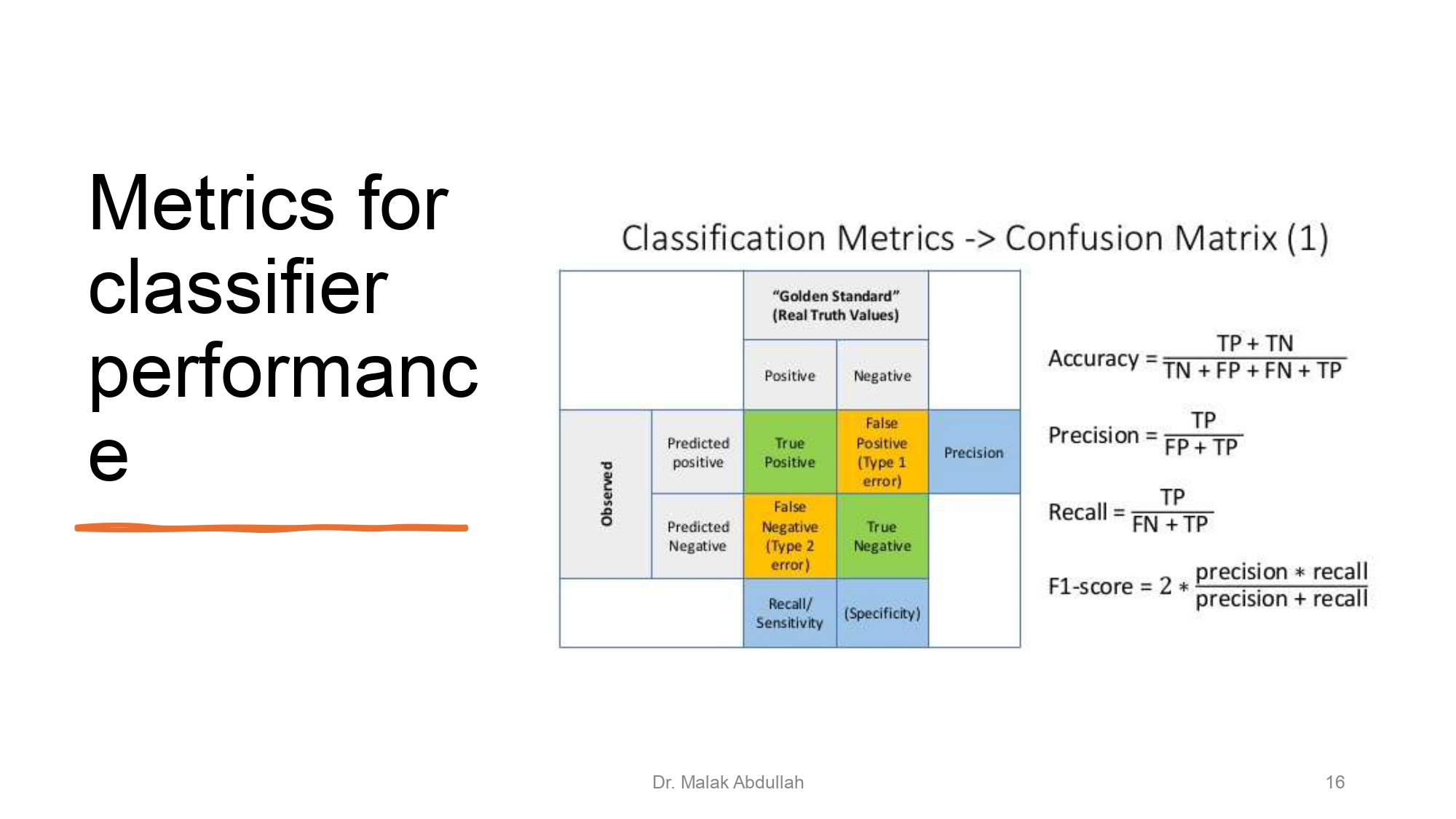
مصفوفة الارتباك (Confusion Matrix) 📉
عشان نعرف الموديل شاطر ولا "هبّاد"، بنستخدم مصفوفة الارتباك، وهي بتعطينا 4 حالات:
True Positive (TP): الموديل قال "صح" وهي فعلاً "صح". (بطل!).
True Negative (TN): الموديل قال "لأ" وهي فعلاً "لأ". (كمان
بطل!).
False Positive (FP): الموديل قال "صح" بس هي طلعت "لأ" (بنسميها
Type 1 error). زي جهاز الإنذار اللي برن وما في سرقة.
False Negative (FN): الموديل قال "لأ" بس هي طلعت "صح" (بنسميها
Type 2 error). وهي الأخطر! زي مريض سرطان والموديل يقوله "إنت
سليم".

مقياس الدقة (Accuracy) 🎯
أبسط مقياس في العالم: كم وحدة حزرنا صح من الكل؟
مشكلة الـ Accuracy: أحياناً بتكون كذابة! لو عنا 100 مريض، 5 منهم معهم سرطان و 95 سليمين.. لو الموديل "هبيد" وبحكي للكل "إنت سليم"، رح تكون دقته 95%! بس هو فعلياً فشل في مهمته الأساسية (كشف الـ 5 مرضى). عشان هيك الـ Accuracy لحالها ما بتكفي.
مشكلة الـ Accuracy: أحياناً بتكون كذابة! لو عنا 100 مريض، 5 منهم معهم سرطان و 95 سليمين.. لو الموديل "هبيد" وبحكي للكل "إنت سليم"، رح تكون دقته 95%! بس هو فعلياً فشل في مهمته الأساسية (كشف الـ 5 مرضى). عشان هيك الـ Accuracy لحالها ما بتكفي.
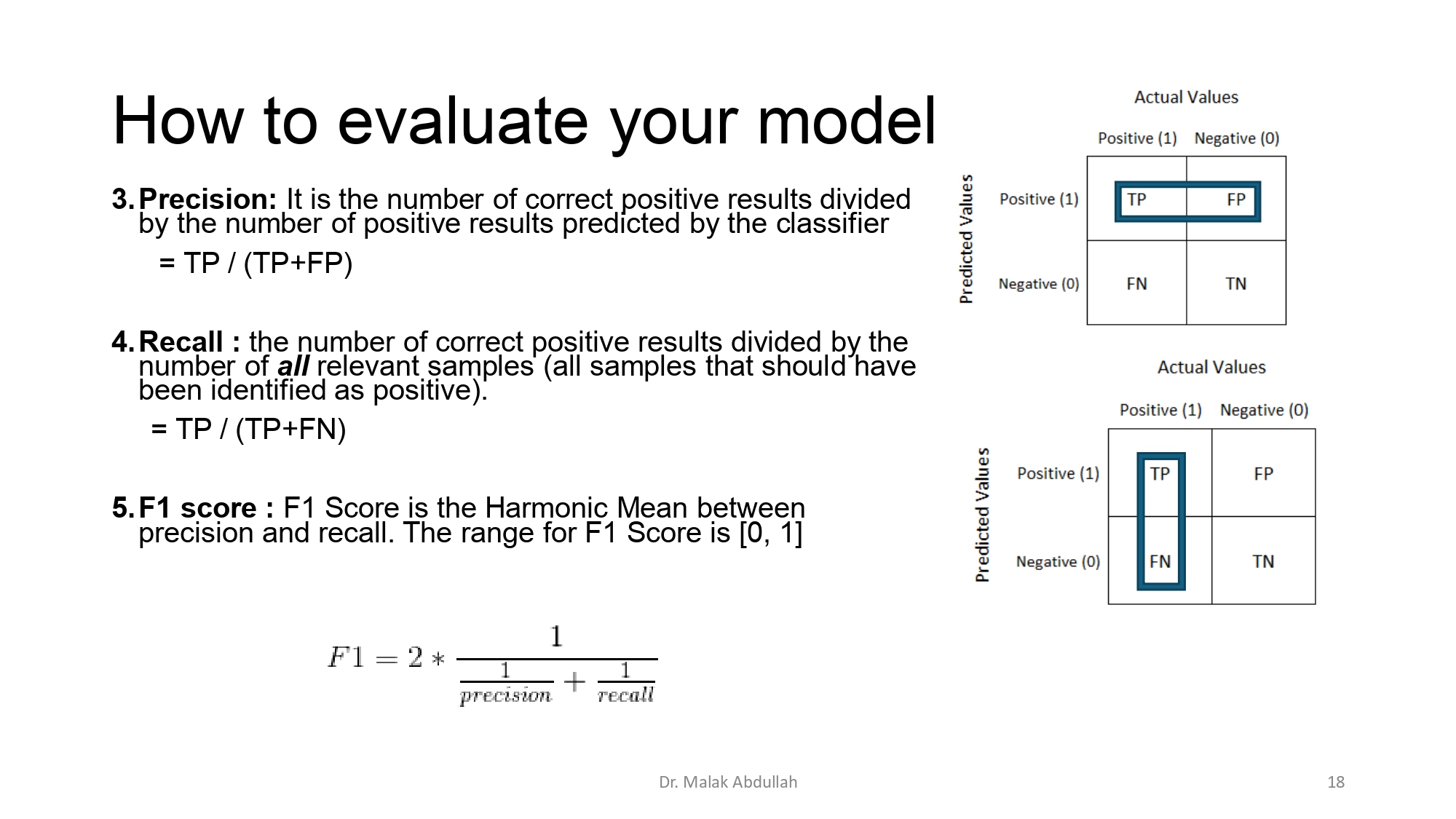
المقاييس الأكثر ذكاءً 🧠
عشان نحل مشكلة الـ Accuracy، بنستخدم:
Precision (الدقة): من كل الأشياء اللي الموديل حكى عنها "صح"، كم
وحدة طلعت فعلاً "صح"؟ (بركز ع الصدق).
Recall (الاسترجاع): من كل الـ "صح" الحقيقي الموجود، كم وحدة
الموديل قدر يلقطها؟ (بركز ع الشمولية).
F1 Score: هو "الوسط" بينهم.. إذا كان عالي، معناه الموديل شاطر
بالـ Precision والـ Recall مع بعض.
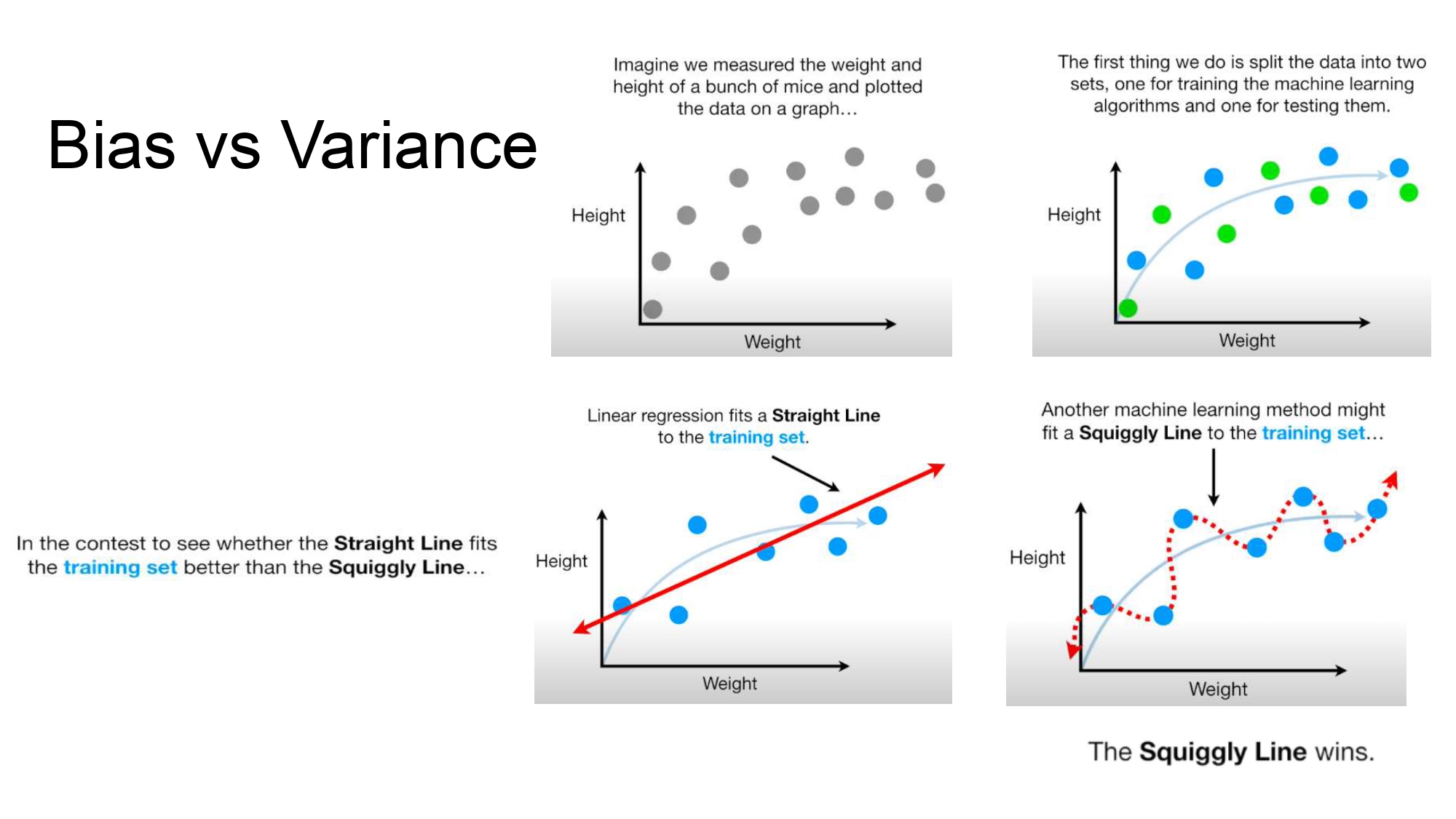
قصة الـ Bias والـ Variance ⚔️
تخيل عنا بيانات لمجموعة فيران (وزن وطول). بدنا نعمل موديل يتوقع الطول بناءً ع الوزن:
Straight Line (خط مستقيم): هاض موديل "بسيط" (Linear
Regression). بحاول يمشي بين النقاط بس مش قادر يلقط كل التفاصيل.
Squiggly Line (خط متعرج): هاض موديل "معقد" ومرن زيادة. مرق في
كل نقطة بالـ Training set بالضبط. بالبداية بتبين إنه هو الفائز لأنه جاب صفر أخطاء بالتدريب.
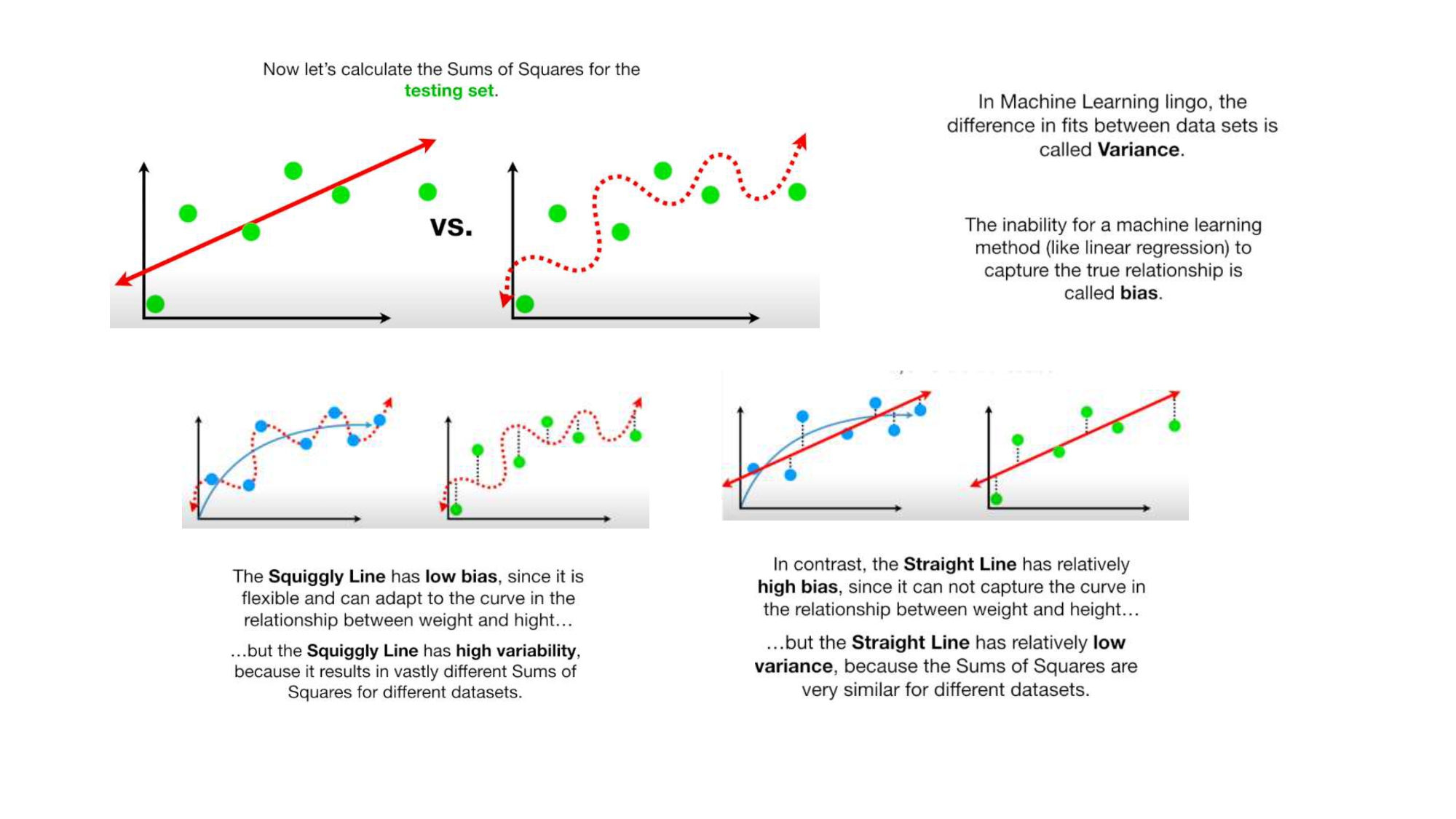
يوم الامتحان يُكرم الموديل أو يُهان! 🏁
لما جربنا الموديلات ع الـ Testing Set (النقاط الخضراء)، انصدمنا
بالنتائج:
Bias (التحيز): هو فشل الموديل (زي الخط المستقيم) إنه يلقط
العلاقة الحقيقية أصلاً. الخط المستقيم "عنيد" ومش راضي ينحني مع البيانات، فدائماً عنده غلط ثابت.
Variance (التباين): الخط المتعرج لما دخل الامتحان فشل فشل ذريع!
الفرق بين أداءه في التدريب (كان بطل) وأداءه في التست (صار سيء) هو الـ Variance. هو "تأثر زيادة"
بتفاصيل داتا التدريب.
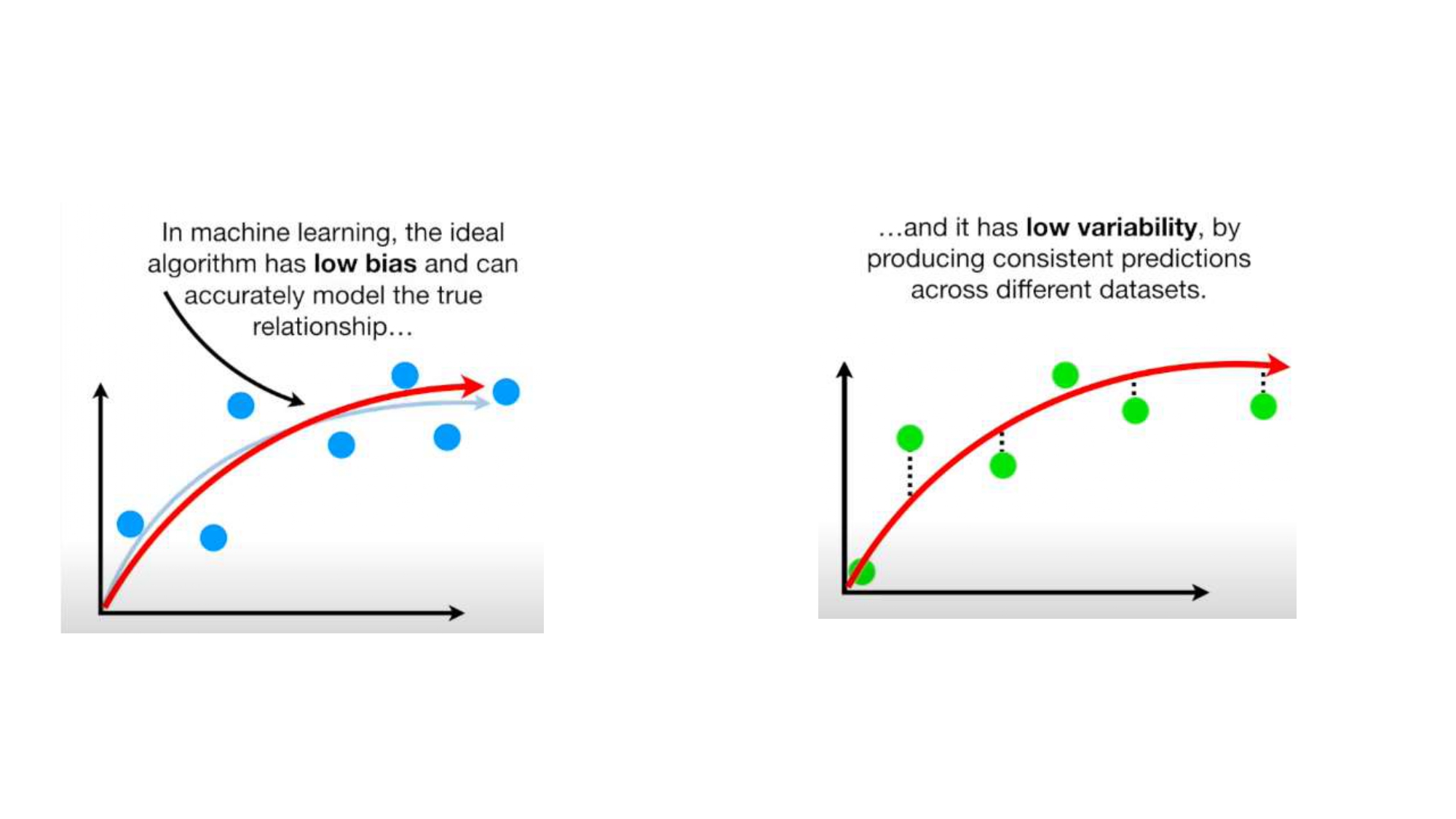
الموديل المثالي (The Sweet Spot) 🎯
الموديل اللي بنحلم فيه هو اللي بجمع بين صفتين:
- Low Bias: يعني فاهم العلاقة الحقيقية بين البيانات ومش "عنيد".
- Low Variance: يعني نتائجه "مستقرة" وما بتتغير بشكل جنوني لما نغير الداتا.

ليش لازم ننقي ميزاتنا؟ (Feature Selection) 💎
لما نتعامل مع نصوص، ممكن يكون عنا مليون كلمة (ميزة). ليش ما نستخدمهم كلهم؟
- الوقت: تدريب مليون ميزة بياخذ وقت طويل جداً.
- الحجم: الموديل بصير حجمه ضخم وبطيء.
- دقة التعميم: في ميزات عبارة عن "شوشرة" (Noise) بتخرب ع الموديل وبتوقعه بالـ Overfitting.

أبسط طريقة للتنقية: التكرار 📈
أسهل إشي ممكن تعمله هو إنك تختار الكلمات الأكثر تكراراً (Commonest
terms):
الكلمات اللي بتتكرر كثير غالباً هي اللي بتعطينا "دليل" قوي ومستقر نقدر نبني عليه توقعاتنا. هاي
الطريقة البسيطة أحياناً بتعطي نتائج خرافية (بتوصل لـ 90% من جودة الطرق المعقدة).

تذكر: الداتا عبارة عن متجهات (Vectors) 📏
عشان الكمبيوتر يفهم النصوص، لازم نحولها لـ Vector Space:
- كل وثيقة هي عبارة عن "سهم" (Vector) في فضاء كبير.
- كل كلمة في قاموسنا هي عبارة عن "محور" (Axis).
- الفضاء بكون عالي الأبعاد جداً (High-dimensional).
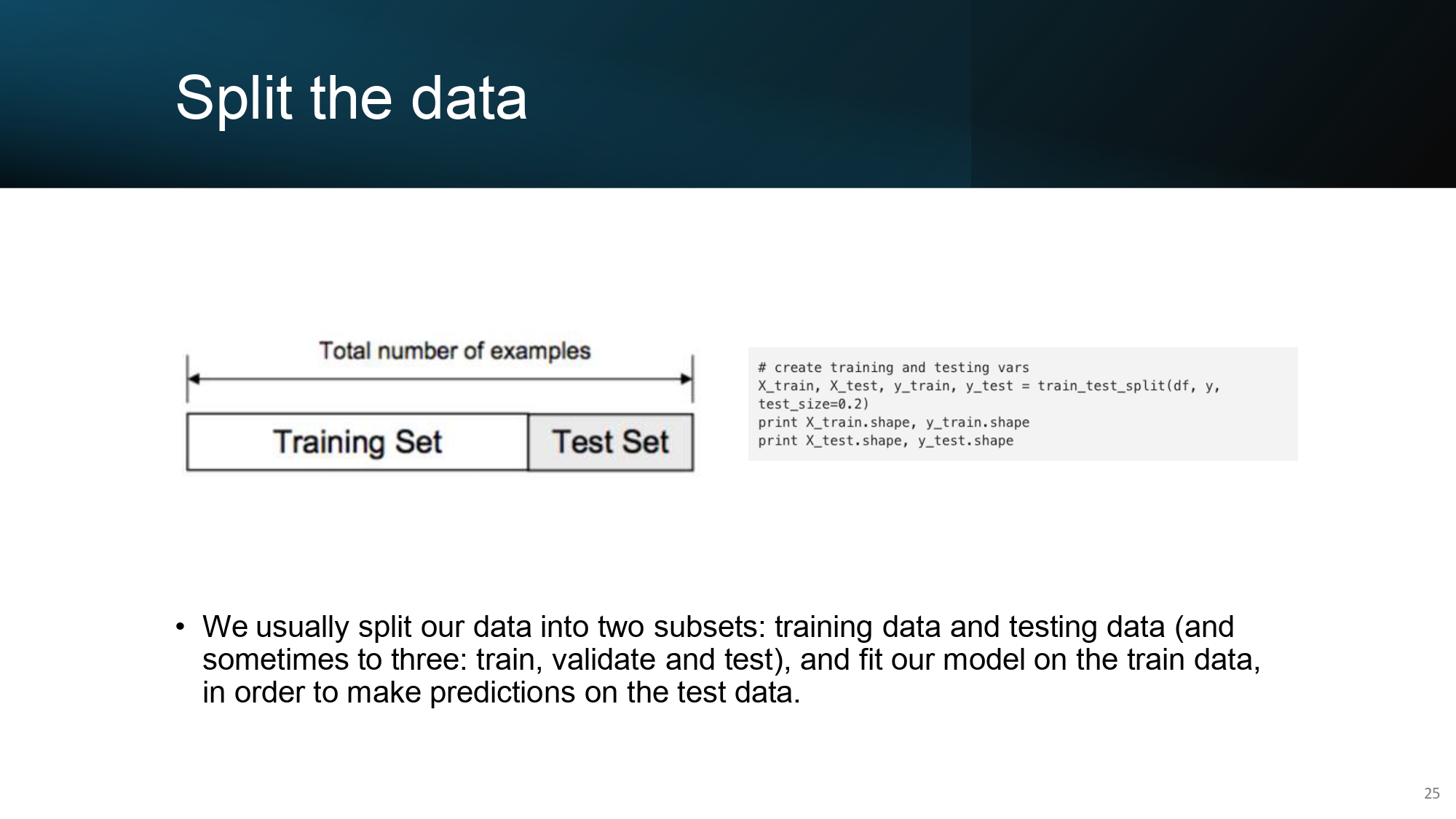
تقسيم الكيكة.. عفواً، البيانات! 🍰📂
قبل ما نبدأ أي إشي، لازم نقسم الداتا لجزئين (أو ثلاثة):
- Training Set: الجزء اللي الموديل رح يدرس منه ويحضر حاله.
- Test Set: هاذ هو "الامتحان النهائي". لازم الموديل ما يشوفه أبداً وقت التدريب عشان نتأكد إنه فهم مش بس بصم.

كيف نكود التقييم؟ 💻🧪
مكتبة sklearn.metrics فيها كل الأدوات اللي بنحتاجها عشان نعرف شو صار
بالامتحان:
accuracy_score: بحسب الدقة الكلية.
f1_score: الميزان اللي بوازن بين الـ Precision والـ Recall.
roc_auc_score: مقياس متطور بعطيك فكرة عن جودة الموديل في
التمييز بين الفئات.
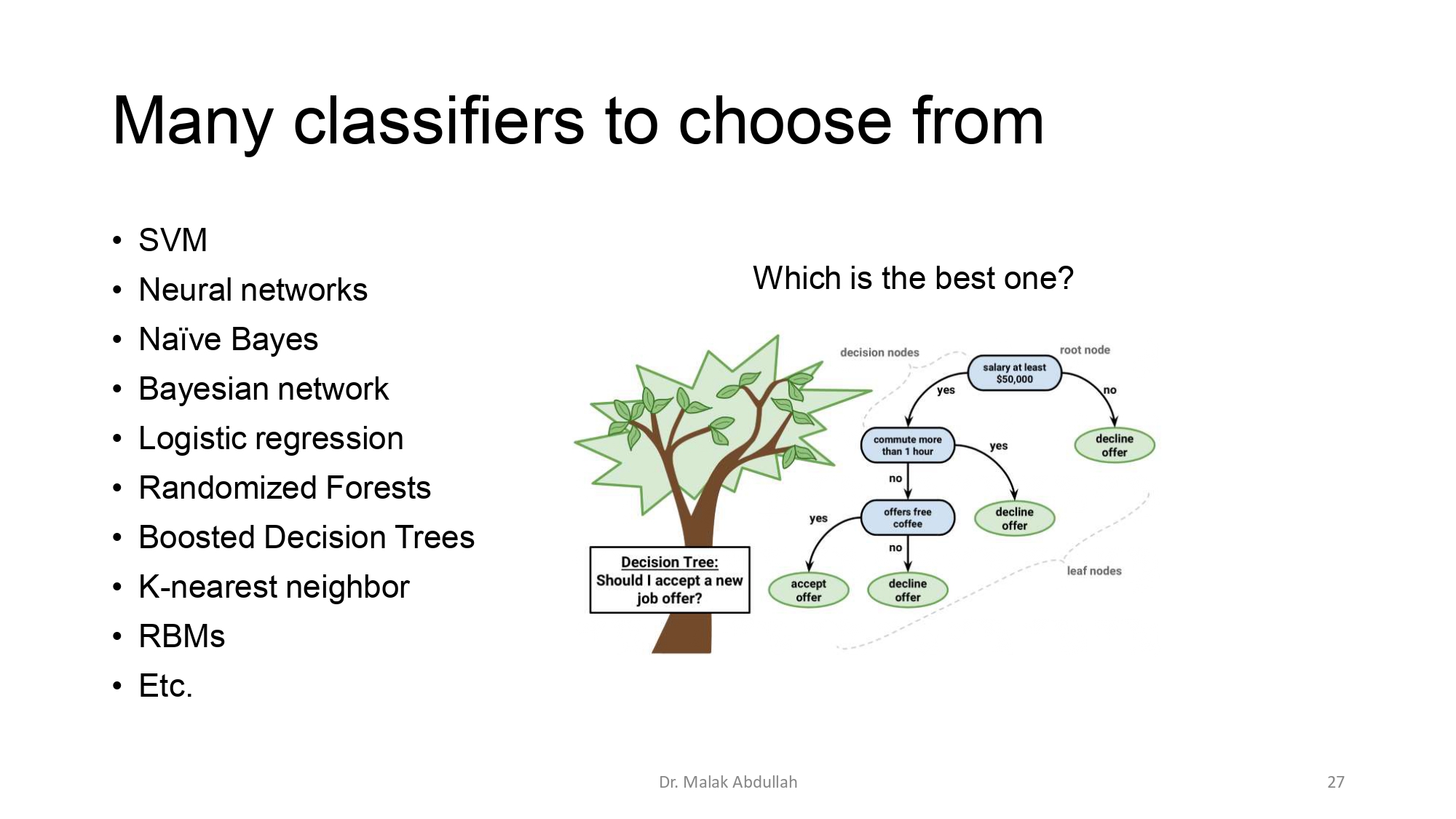
بحر من المصنفات (Classifiers) 🌊🤖
عنا خيارات كثيرة جداً، وكل واحد إله ميزاته:
- SVM & Neural Networks: موديلات قوية ومعقدة.
- Decision Tree (شجرة القرار): بتشتغل زي خوارزمية "نعم أو لا". زي لما تقرر تقبل وظيفة بناءً ع الراتب والمسافة.
- Naïve Bayes: مشهور جداً بتصنيف النصوص (زي كشف الإيميلات السبام).
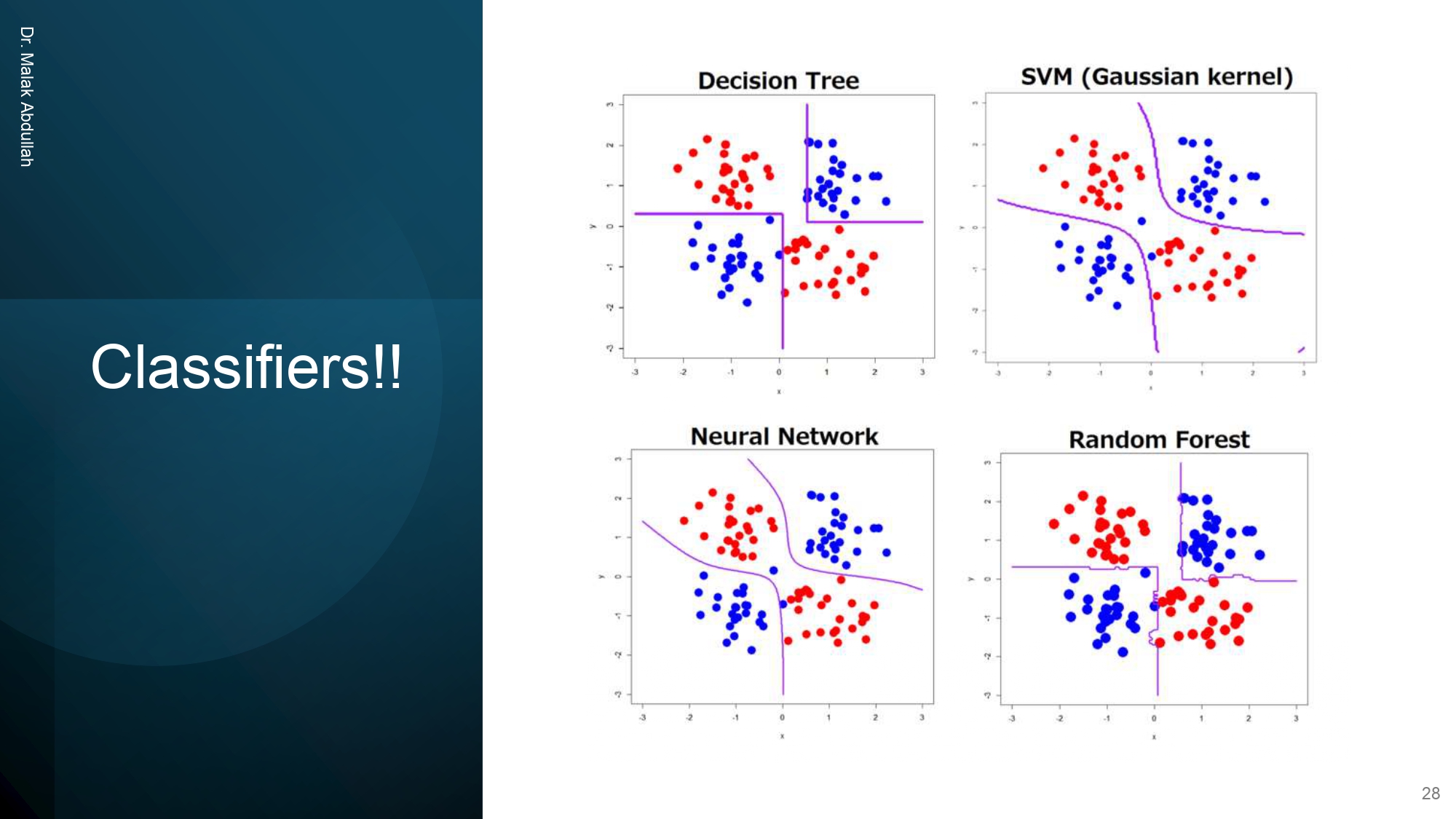
كيف الموديلات بتشوف العالم؟ 👀🗺️
الصورة بتورجينا كيف كل موديل بفصل بين النقاط الحمراء والزرقاء:
- Decision Tree: بقسم الفضاء لـ "مربعات" وخطوط مستقيمة زاوية.
- SVM & Neural Network: بقدروا يعملوا حدود "منحنية" وناعمة ليفصلوا بين النقاط بشكل أدق.
- Random Forest: بحاول يجمع بين كذا شجرة قرار ليعطيك تقسيم منطقي أكثر.

أسئلة لازم نسألها حالنا 🧐❓
لما نختار موديل، في أسئلة جوهرية:
- مين الأفضل؟ هل اللي بجيب دقة عالية بالتدريب هو الأفضل؟ (تذكر الـ Overfitting!).
- التعقيد: هل الموديل المعقد دائماً أحسن، ولا البساطة مطلوبة أحياناً؟
- المستقبل: شو بصير بالموديل لما نزيد الداتا؟ هل بصير أشطر ولا ببطئ؟
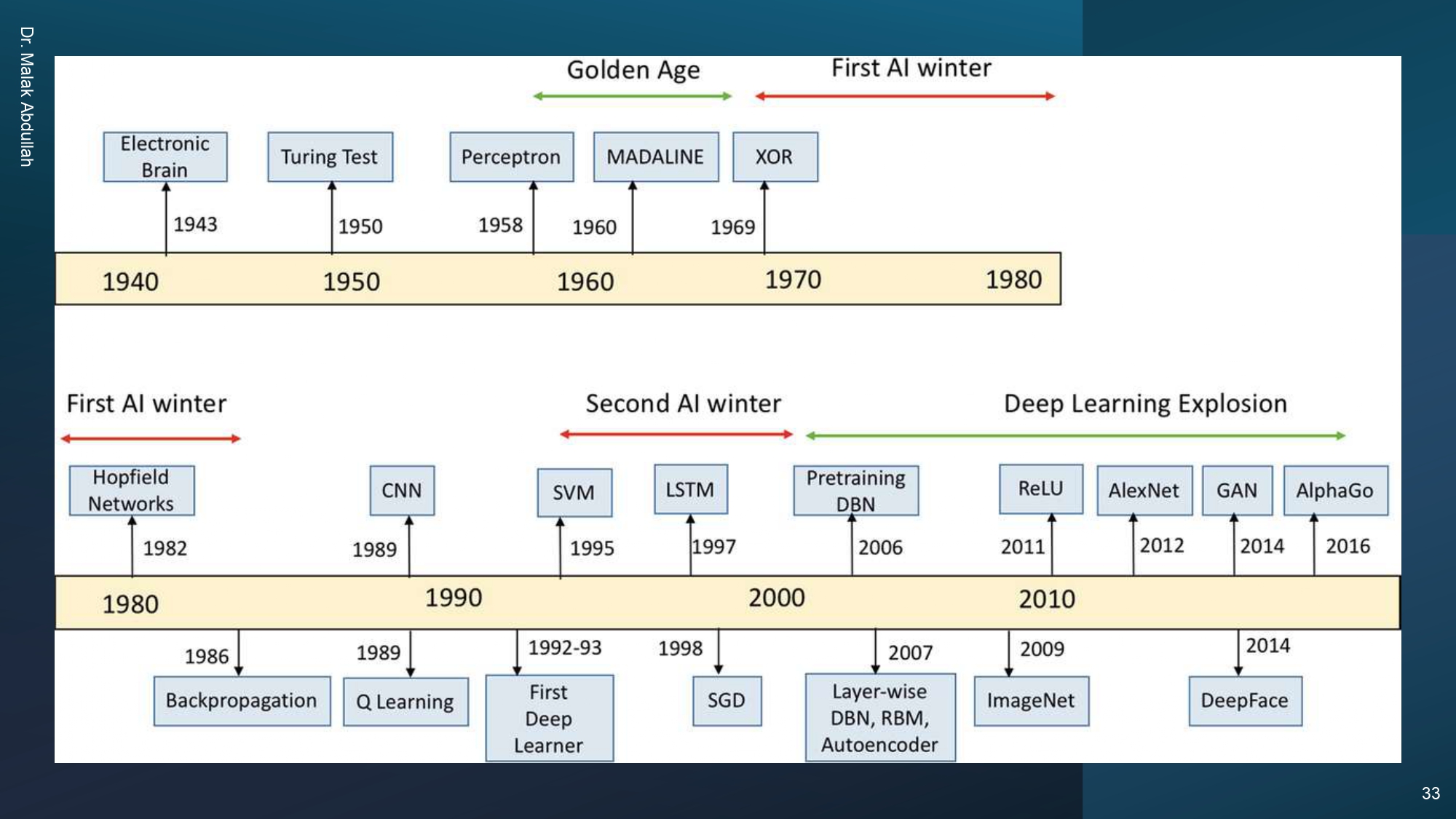
تاريخ الذكاء الاصطناعي (أيام زمان وهسا) ⏳📜
تاريخ الـ AI مليان مطبات وحماس:
العصر الذهبي (1950s - 1960s): وقت تورينج وأول محاولات لمحاكاة
العقل.
شتاء الذكاء الاصطناعي (AI Winter): صار مرتين (السبعينات
والتمينات) لما الناس فقدت الأمل وتوقف الدعم.
انفجار الـ Deep Learning (2010 - اليوم): بفضل الـ ReLU والـ
AlexNet والـ Transformers، صرنا في العصر الذهبي الحقيقي.
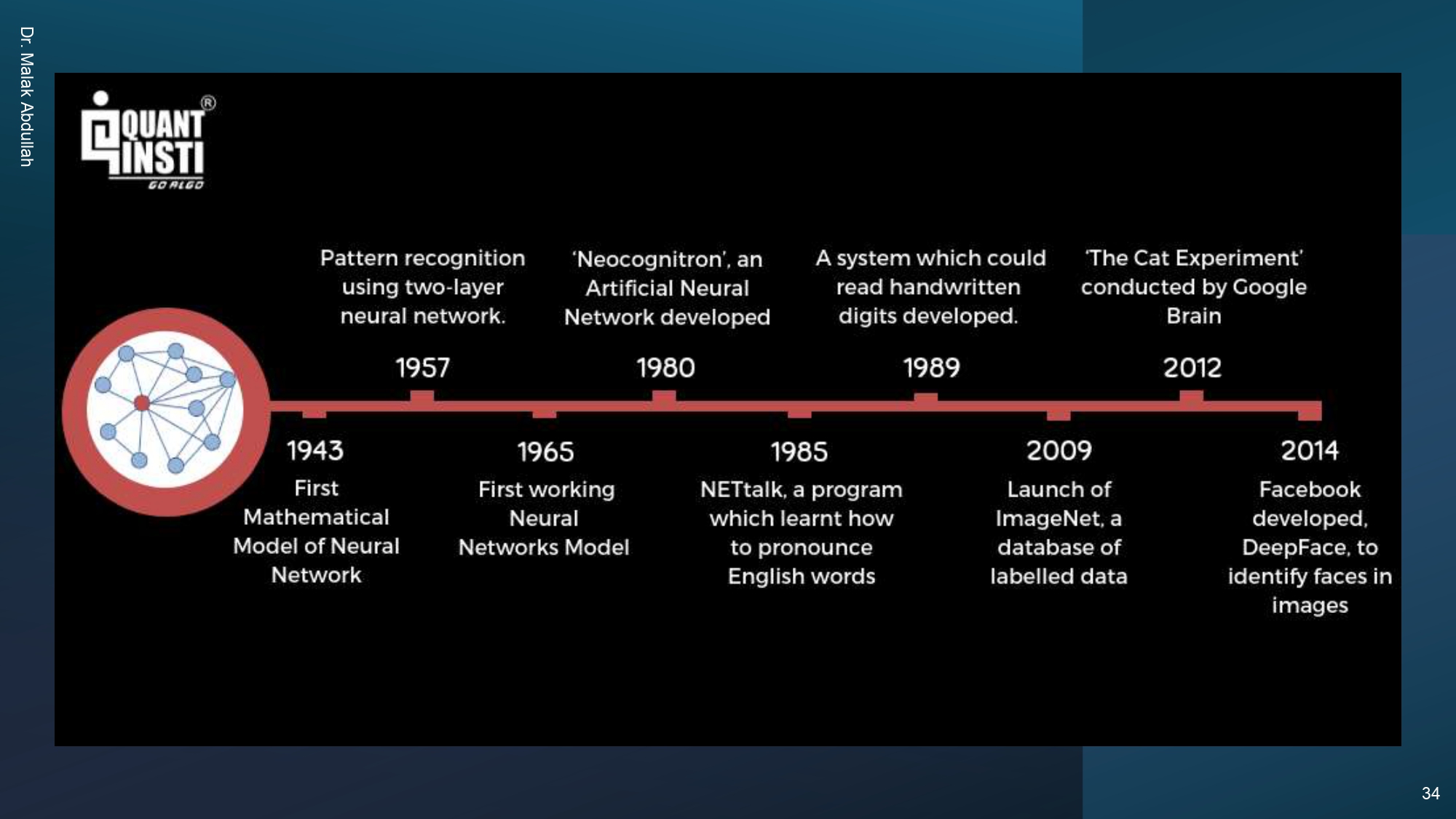
محطات غيرت مجرى التاريخ 🚉🏆
خلينا نشوف اللحظات الفاصلة:
- 1943: أول موديل رياضي للخلية العصبية.
- 1989: أول نظام بيعرف يقرأ خط اليد.
- 2012: تجربة "القطة" من جوجل، و 2014 تجربة الـ DeepFace من فيسبوك.

ليش الـ Neural Networks رجعت وبقوة؟ 🔄🔥
الفكرة قديمة من الأربعينات، بس في التسعينات خسروا قدام الـ SVM (الـ Kernel Trick كان مسيطر).
لكن من بعد الـ 2011، الشبكات العصبية العميقة اكتسحت كل إشي. ليش؟ لأن الحواسيب صارت مرعبة والداتا
صارت متوفرة بكل مكان، والـ SVM ما قدر يواكب هاض الحجم الهائل.

السر في قوة الـ NN هسا ⚡🔌
في 4 أسباب خلت الـ Deep Learning ينفجر:
- داتا عملاقة: التدريب بطل ع عينات صغيرة، صار ع تريليونات البيانات.
- قوة الحوسبة (GPUs): كروت الشاشة خلت التدريب أسرع بآلاف المرات.
- خوارزميات أذكى: تحسينات بسيطة في الرياضيات (زي الـ ReLU) عملت فرق جبار.
- الدعم المادي: الشركات الكبيرة صارت تضخ مليارات بالبحث والتطوير.
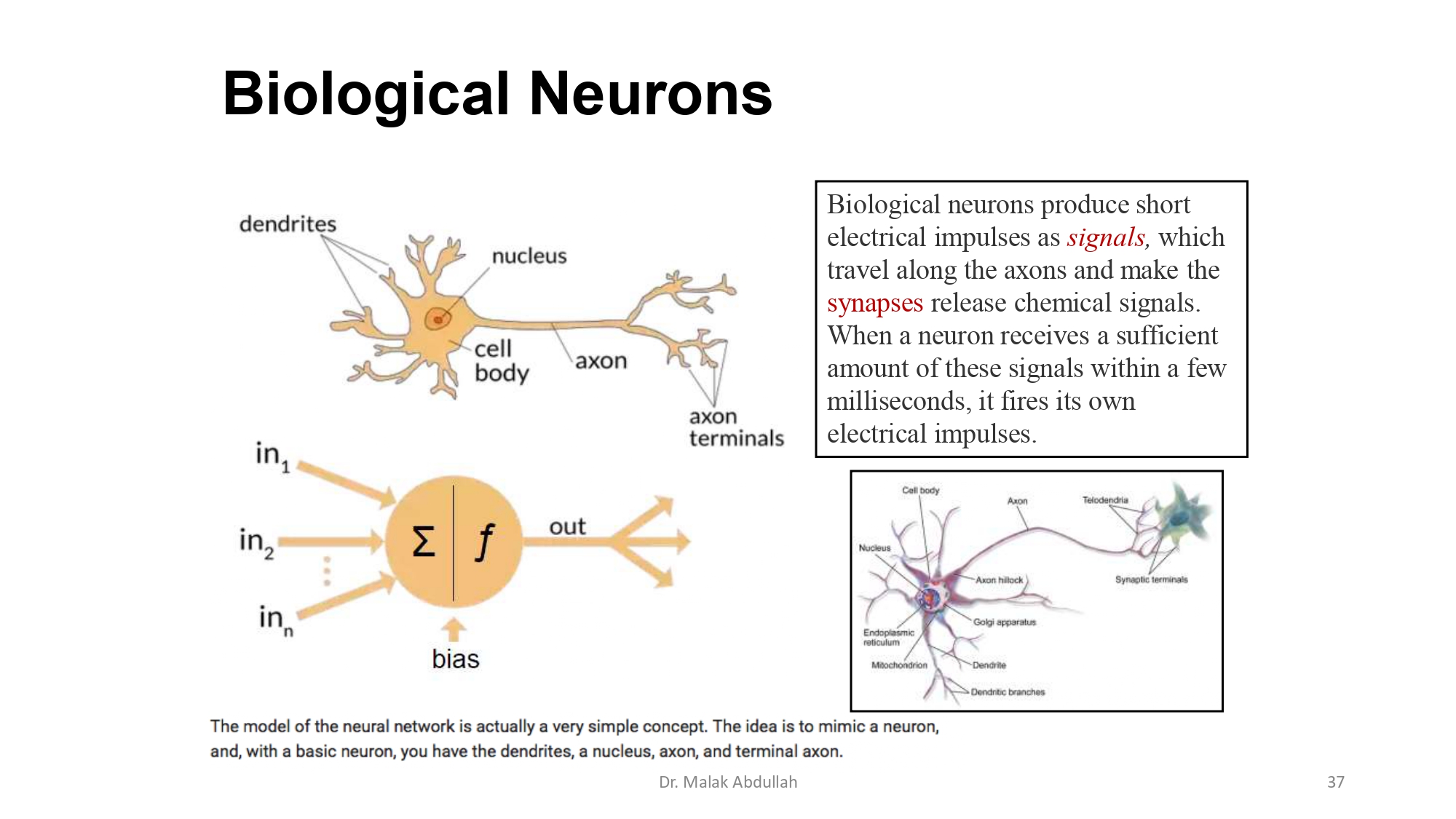
الإلهام من الطبيعة (مخ الإنسان) 🧬🧠
الـ Artificial Neural Network مستوحاة من عصبونات مخنا:
- Dendrites (المدخلات): بتستقبل الإشارات من برا.
- Cell Body/Nucleus: هون بتم معالجة الإشارة.
- Axon (المخرجات): بتنقل النتيجة للعصبونات الثانية.
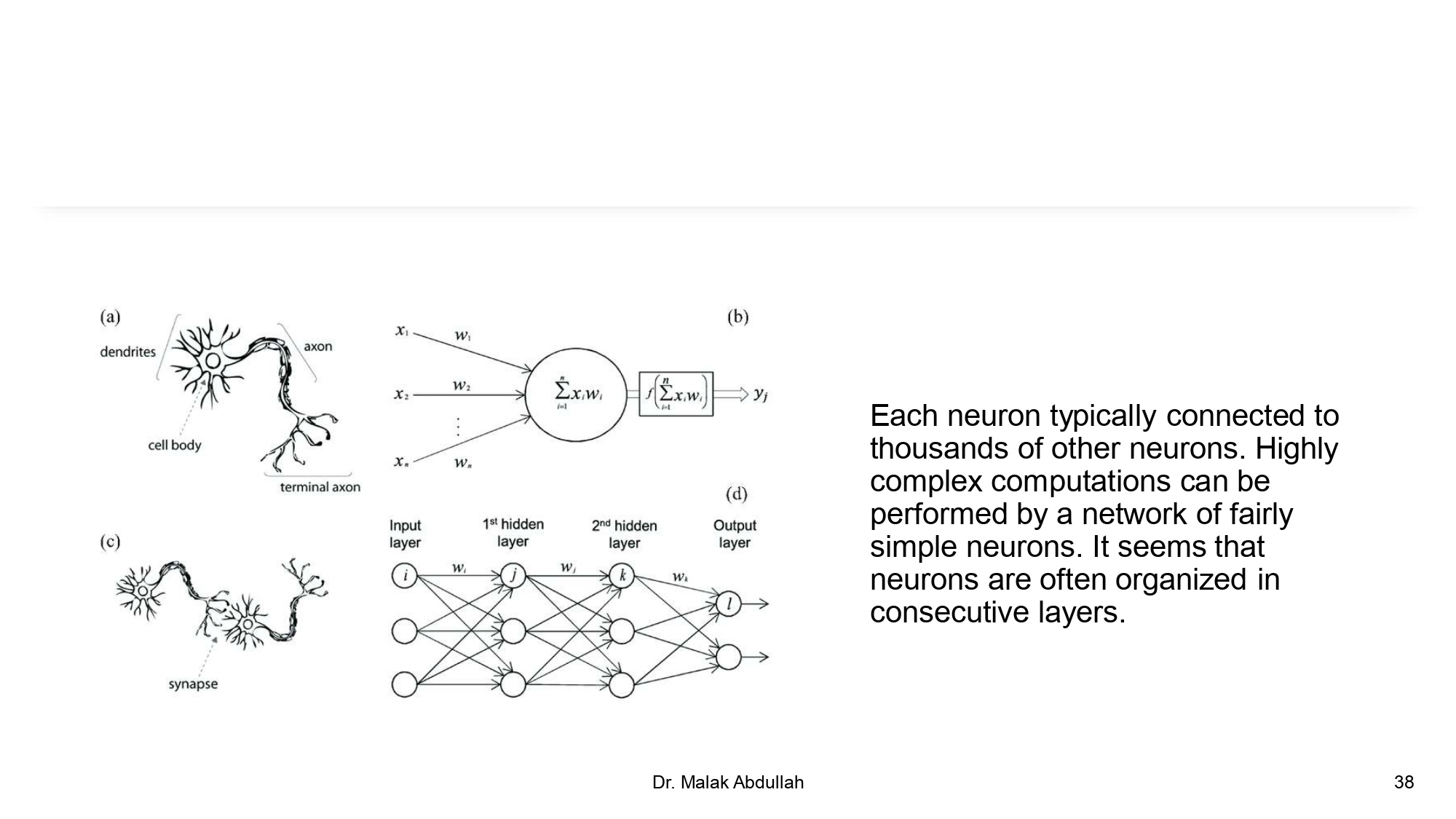
التشابك والطبقات (The Network) 🕸️🏗️
العظمة بتيجي لما نربط هاي العصبونات ببعض:
الشبكة بتتكون من Input layer، و Hidden
layers، و Output layer. المعلومات بتمر عبر "أوزان"
(Weights) بتتغير وقت التدريب عشان الموديل يتعلم الصح من الخطأ.
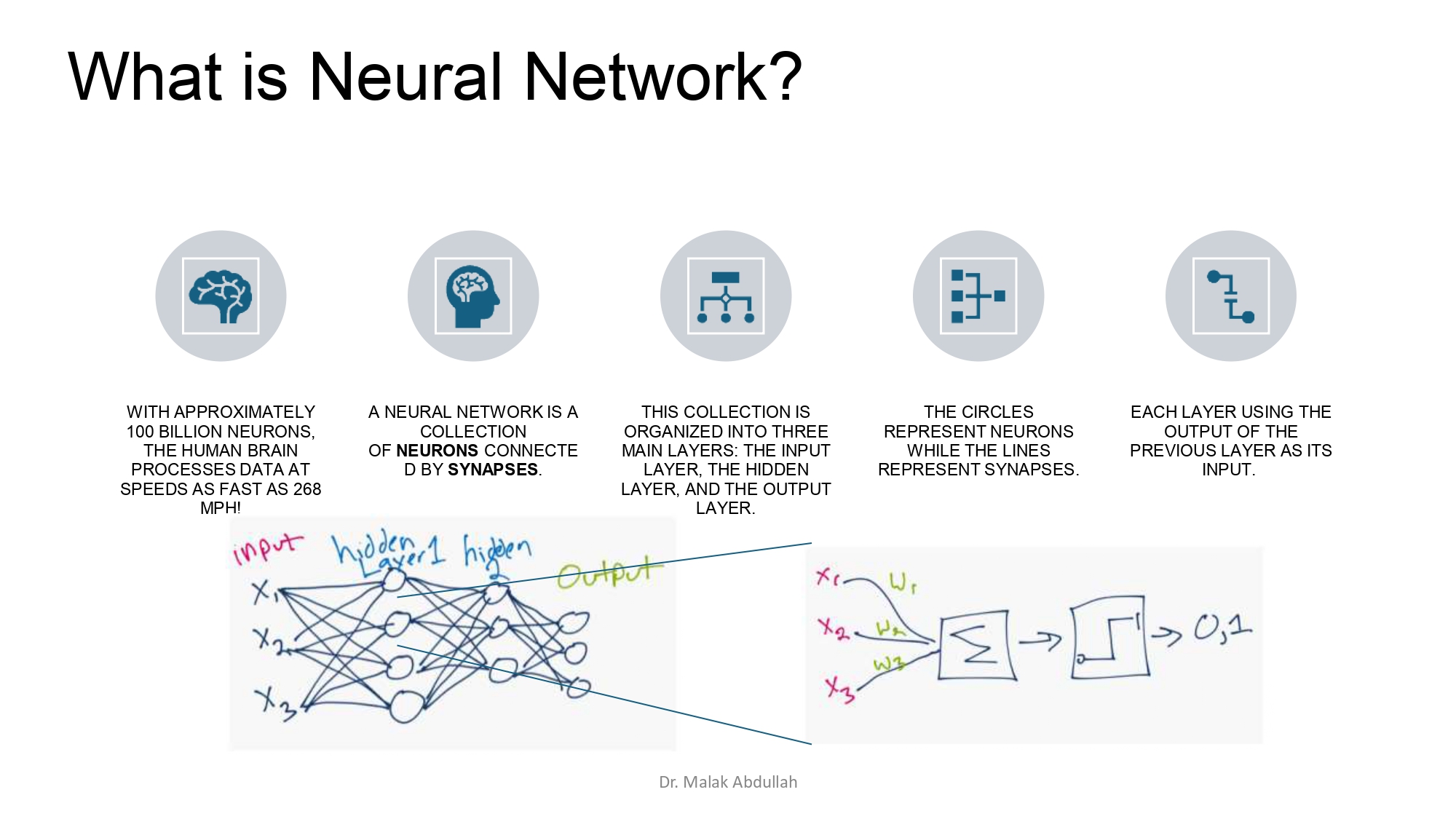
شو يعني شبكة عصبية أصلاً؟ 🤔🧠
عقل الإنسان فيه حوالي 100 مليار عصبونة بتعالج المعلومات بسرعة خيالية.
- التعريف: هي مجموعة عصبونات مرتبطة ببعضها عن طريق "تشابكات" (Synapses).
- الطبقات: بتتقسم لـ Input، و Hidden، و Output.
- التسلسل: مخرجات كل طبقة بتصير هي المدخلات للطبقة اللي بعدها.
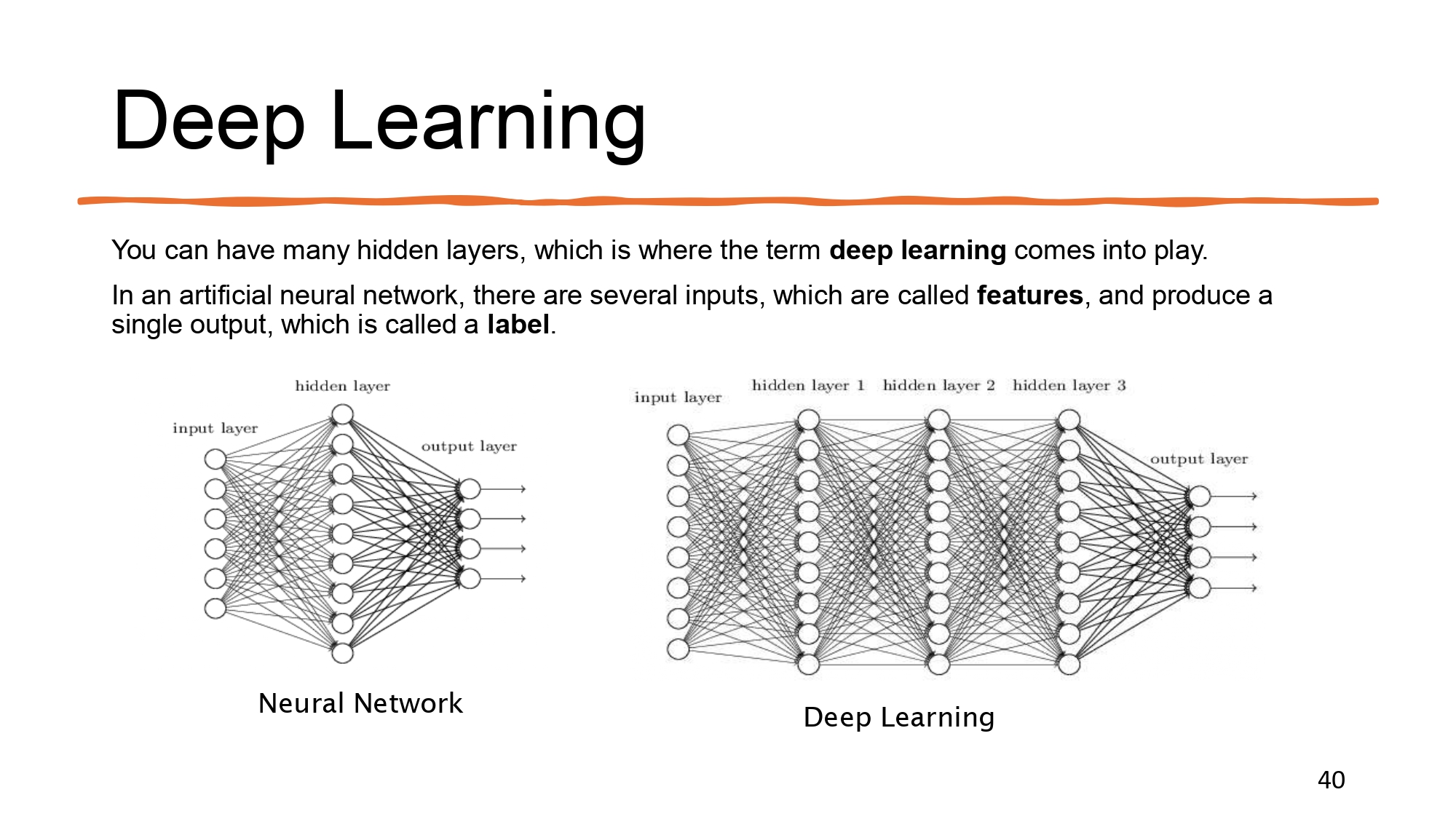
ليش سمه "عميق" (Deep)؟ 🧱🌊
كلمة "عميق" بتيجي من كثرة الـ Hidden Layers.
لما يكون عندنا طبقات مخفية كثيرة، الموديل بصير عنده قدرة جبارة على استخراج أنماط معقدة جداً من
الداتا. المدخلات بنسميها Features، والنتيجة النهائية هي الـ
Label أو التوقع.

التعلم بالمثال (Learning by Example) 🎓📖
الـ Deep Learning بخلي الكمبيوتر يتعلم زي البشر: بالممارسة والأمثلة.
- عنده دقة بتنافس (وأحياناً بتغلب) دقة الإنسان.
- بقدر يتعامل مع الصور، النصوص، والأصوات مباشرة.
- هو المحرك الأساسي لتقنيات المستقبل زي السيارات ذاتية القيادة.

آلية العمل الذاتية ⚙️🤖
أهم ميزة هون هي الـ End-to-End learning:
- بدون تدخل بشري: الشبكة هي اللي بتطلع الـ Features لحالها من الداتا الخام.
- المتطلبات: عشان يشتغل صح، بدك GPU قوي وكميات داتا ضخمة جداً (آلاف الصور على الأقل).
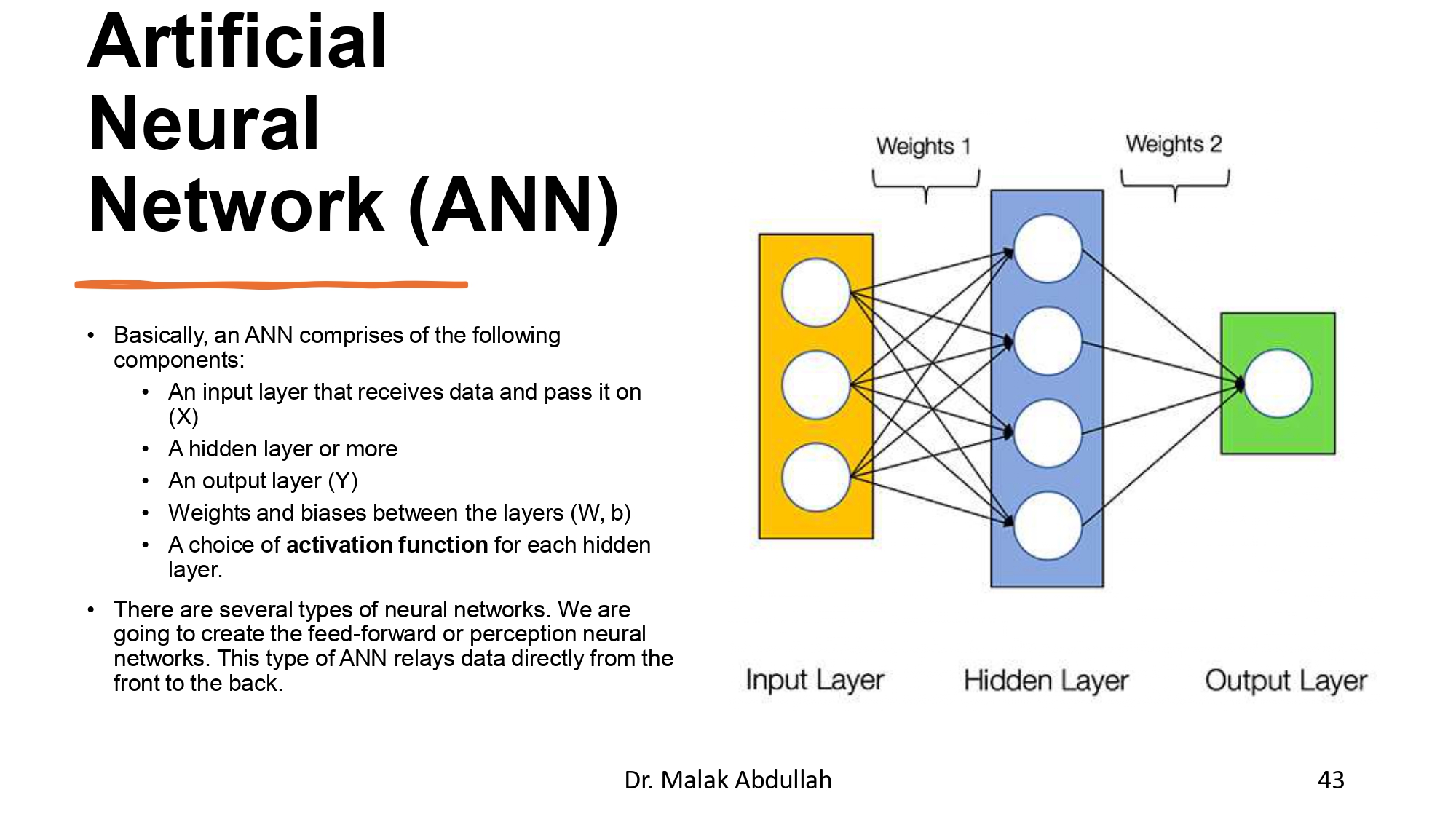
مكونات الـ ANN بالتفصيل 🧱🔍
أي Artificial Neural Network بتتكون من:
- Input Layer: بتستقبل الداتا (X).
- Hidden Layers: هون بتم الشغل والتعقيد.
- Output Layer: بتعطي النتيجة النهائية (Y).
- Weights & Biases: الأرقام اللي الموديل بضل يعدل فيها ليتعلم.
- Activation Function: اللي بتقرر هل العصبونة "تشتغل" ولا لأ.

الفرق الجوهري بين الـ Machine والـ Deep ⚔️⚖️
في الـ Machine Learning التقليدي، الإنسان لازم يختار المميزات
(Manual Feature Extraction) والموديل بس بصنف.
أما في الـ Deep Learning، عملية استخراج المميزات والتصنيف كلها
بتصير "أوتوماتيك" جوا الشبكة.

طرق التدريب: من الصفر ولا "جاهز"؟ 🛠️🏗️
عندك طريقتين للتدريب:
- Train from Scratch: تبني كل إشي من الصفر، وهاض بده وقت كبيييير وداتا هائلة.
- Transfer Learning: تستخدم موديل ذكي أصلاً (زي AlexNet) وتعدل عليه شوي ليناسب شغلك. هاي الطريقة أسرع وبدها داتا أقل بكثير.
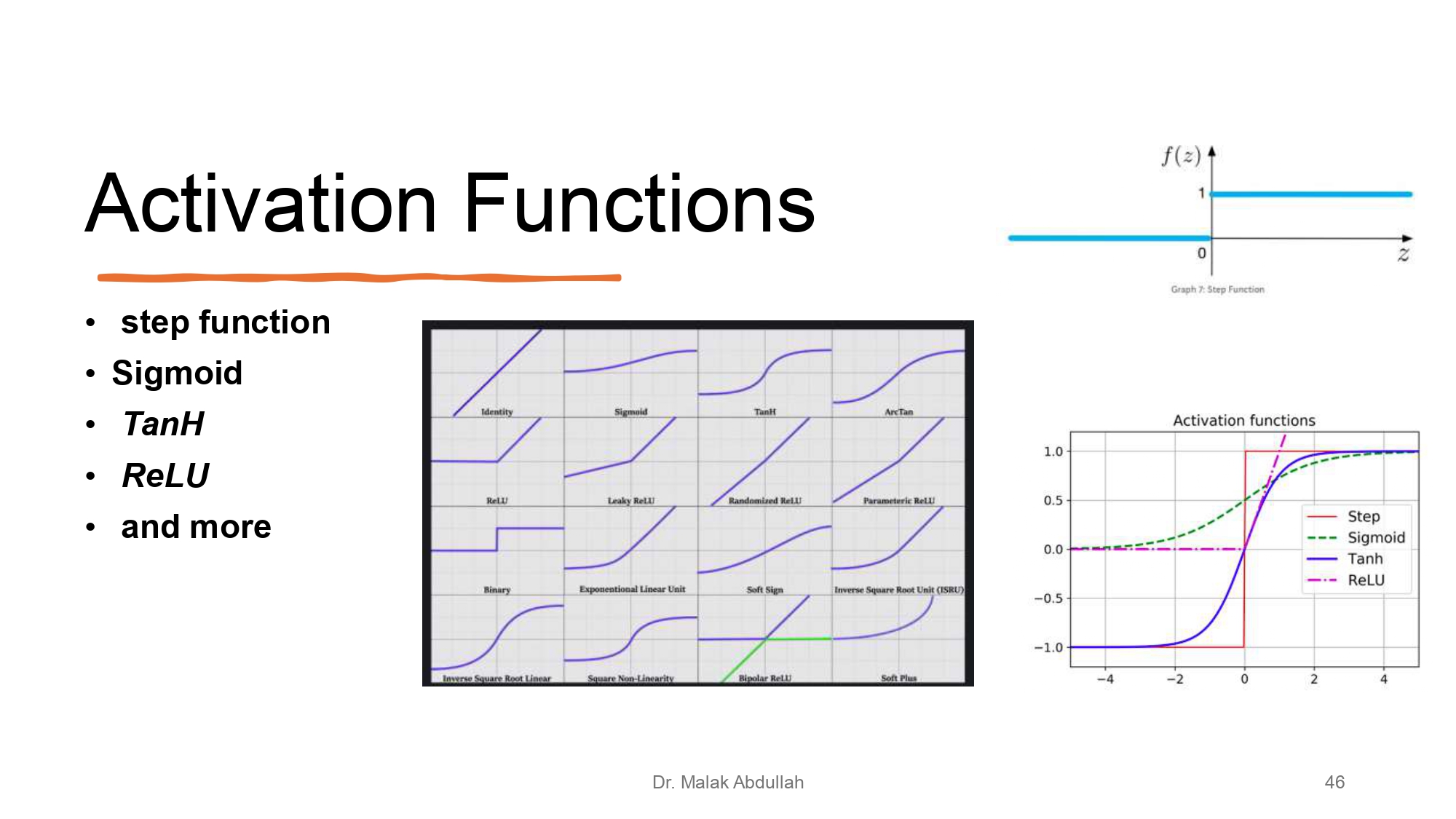
دوال التنشيط (Activation Functions) ⚡📈
هي الدوال اللي بتعطي "الروح" للشبكة وبتحولها من مجرد ضرب مصفوفات لشي قادر يفهم العلاقات غير الخطية:
- Sigmoid / TanH: مشهورين بس فيهم مشاكل بالتدريب العميق.
- ReLU: البطل الحالي، بسيط وسريع وبحل مشاكل كتير.
- Step Function: أبسط نوع (يا 0 يا 1).

الخلاصة الممتعة
زي ما قال فورست غامب: "الحياة مثل صندوق من الشبكات العصبية، ما بتعرف شو رح يطلعلك!"
الـ Deep Learning بحر واسع، وكل يوم فيه إشي جديد. أهم إشي تضل فاهم
الأساسيات صح عشان تقدر تواكب الجنون اللي بصير في هاض المجال